There is one basic document functionality that none of HTML, CSS, nor SVG can do. None can represent one box, another box, and a link between the two.
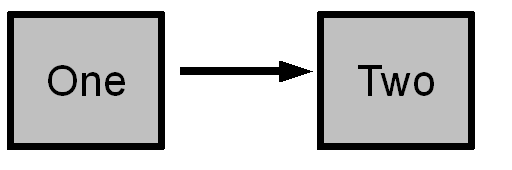
The most fundamental feature of HTML is the hyperlink, But while
〈a id="one" href="#two"〉Linking to #two〈/a〉
〈a name="two"〉Linked to from #one〈/a〉
could be represented by the above graphic, a HTML hyperlink doesn’t represent this itself.
CSS is good at drawing boxes, but it can’t show relationships between boxes. Using CSS there would be something missing between boxes one and two.
SVG can draw the rectangles and with a little trouble an arrow between the two. However it will do this as three unconnected graphics, two boxes and one arrow. This doesn’t represent any relationship between the boxes. As far as SVG is concerned the middle graphic could just as well be a tiger between two rabbits.
(more…)